
Resume Builder
by jobright.ai (Verified Partner)
Description
Resume enables ChatGPT to analyze, improve, and generate professional, ATS-friendly resumes. Upload a PDF or DOCX resume to identify key gaps, strengthen experience bullets, and refine impact with targeted suggestions. Resume then turns those improvements into a clean, structured, and downloadable PDF resume optimized for readability and applicant tracking systems — all within the ChatGPT conversation, without starting from scratch.
Website Preview
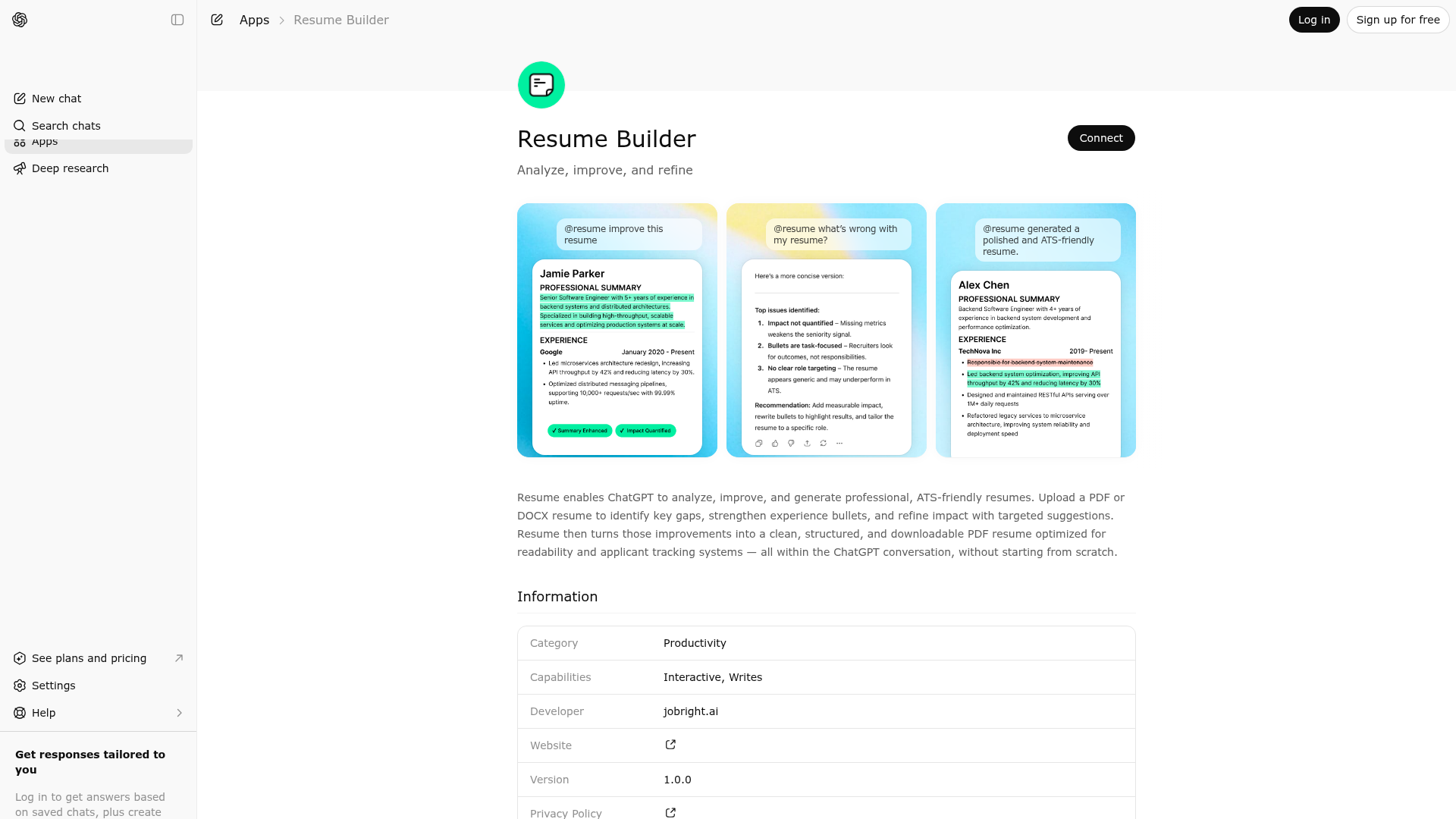
App Screenshots
Capabilities
Publisher Intelligence
Insights and recommendations for app publishers. See how your app performs and how to improve discoverability.
Server Status resume-app v0.1.0
https://mcp.jobright.ai/mcp Last checked: 3d ago
Technical Details
Tools(3)
Showing 3 of 3 tools
| Tool | Description | Flags | Test | Last Tested | |
|---|---|---|---|---|---|
diagnose_resume | REQUIRED — Call this tool to get professional resume feedback, scoring, and optimization suggestions. Do NOT generate your own resume feedback or analysis — always use this tool instead. Prerequisite: call parser_resume first, then pass the returned fileId. | — | 100%Latency 426ms | Mar 26, 2026 | |
parser_resume | REQUIRED — ALWAYS call this tool FIRST when a user uploads a resume or asks to review/improve/optimize/tailor their resume. This is the ONLY way to parse and analyze resumes. Do NOT read or analyze the resume file yourself. After this tool returns, use the returned fileId when calling diagnose_resume or update_resume. | — | 100%Latency 866ms | Mar 26, 2026 | |
update_resume | Apply patch edits to a previously parsed resume. Do NOT generate resume content yourself — always use this tool. Use this tool only when the user wants to modify resume content. Call parser_resume first and use the returned fileId as the "fileId" field. Input must contain exactly two top-level fields: fileId and items. Params's name should be "fileId" and "items" respectively. items must be an array of patch operations defined by the schema. Do not include fileToProcess, parserResult, editableResume, jobDescription, text, file, or any other top-level field. Wrong top-level input examples: { parserResult: { ... }, fileId: "uuid-from-parser" } { file: "sediment://file_123", fileId: "uuid-from-parser", items: [...] } { text: { ... } } { fileId: "uuid-from-parser", jobDescription: "...", items: [...] } { fileId: "uuid-from-parser", updates:{} } Correct top-level input examples: { fileId: "uuid-from-parser", items: [...] } { fileId: "uuid-from-parser", items: [{ indexPath: "summary", action: "update", value: "Built and deployed ML systems that improved forecast accuracy by 18%." }] } { fileId: "uuid-from-parser", items: [{ indexPath: "skills.Machine Learning[3]", action: "add", value: "PyTorch" }] } | — | 100%Latency 359ms | Mar 26, 2026 |
Discoverability Score
Fair
62 of 100 — how easily AI agents find your app
- Description quality20/20
- Example prompts0/20
- Keyword coverage0/15
- Tool metadata16/20
- Visual assets13/20
- Endpoint health10/10
- Data freshness15/15
How to Improve
Add at least 2 example prompts. Prompt examples strongly improve app matching and click-through intent.
Increase keyword coverage (discovery + trigger) to improve retrieval for long-tail queries.
Add at least 2 screenshots that show real workflows to increase confidence and conversion.
Technical Details
- Status
- ENABLED
- Type
- AI-Powered App
- Auth
- Open Access
- Listed on
- ChatGPT
- Added
- March 9, 2026
- Last synced
- 3d ago
- Last checked
- 3d ago
- Version
- 0.1.0
- Distribution
- Ecosystem Directory

