Parallel Search
by Parallel Web Systems (Community)
Description
Parallel Search provides drop-in web search and content extraction capabilities. The tools invoke the Search API and Extract API endpoints and ensure effective use by agents. Find content on the web without wasting tokens.
Website Preview
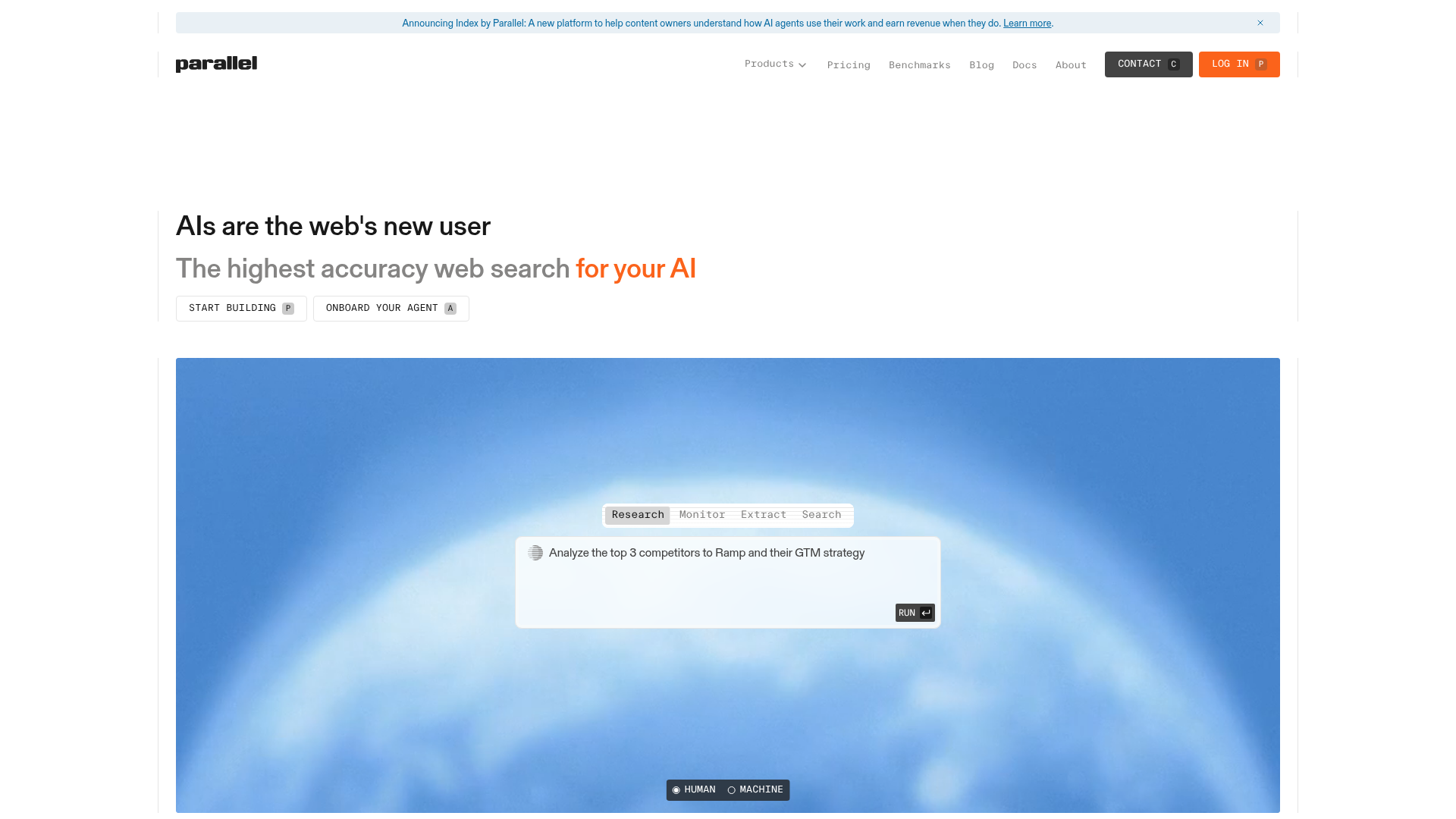
App Screenshots
Capabilities
No special capabilities listed
AI Agent Discovery
Parallel Search is indexed by Tedix as a structured developer tools listing for AI assistants, search crawlers, and users comparing agent-ready apps.
- Parallel Search is categorized as Developer Tools.
- Developer: Parallel Web Systems.
- Connector type: AI-Powered App.
- Current connector status: Connected.
- Observed distribution channels: chatgpt.
- Available regions: US, FR, GB, ES, KR, IN.
Use this page to understand whether Parallel Search is relevant for developer tools workflows in AI assistants.
For MCP discovery, this listing helps crawlers connect Parallel Search to tool, resource, prompt, and server-health signals instead of treating it as a generic directory entry.
The canonical Tedix directory URL is https://tedix.dev/apps/parallel-search/.
Crawlable Profile
Source and availability
Tedix identifies Parallel Search from Upstream Mcp tool source; Store sources: ChatGPT app store; Distribution: Ecosystem Directory. Availability is reported for US, FR, GB, ES, KR, IN.
- ChatGPT app store Auth not flagged · RELEASED · US, FR, GB, ES, KR, IN
Auth, tools, and actions
Authentication: Open Access. No special capability flags are currently listed. Current MCP inventory reports 2 tools, 0 resources, and 0 prompts.
- web_fetch · Read-only action
Purpose: Fetch and extract relevant content from specific web URLs. Use only when web_search excerpts are insufficient for the task at hand. Ideal Use Cases: - The user asked about a specific URL or page - You need exact wording or quotes that excerpts may have truncated - You need full-page analysis (long article, document, or page structure) - web_search excerpts are conflicting or clearly insufficient to answer
- web_search · Read-only action
Purpose: Perform web searches and return LLM-friendly results, including excerpts that are usually sufficient to answer directly without a follow-up fetch. Ideal Use Cases: - Answering questions that require fresh or current information - Research, comparison, documentation, and troubleshooting questions - Broad tasks where multiple `search_queries` can be issued in a single call
Verification freshness
- Catalog synced 1d ago (June 5, 2026)
- Connector checked May 30, 2026
- MCP scanned May 30, 2026
- Website enriched May 28, 2026
- Directory updated 1d ago (June 5, 2026)
Alternatives and related apps
Comparable apps in Developer Tools include 3Min API, Adalo, Airbyte Agent Engine, Alchemy.
Publisher Intelligence
Insights and recommendations for app publishers. See how your app performs and how to improve discoverability.
Server Status Parallel Web Search MCP Server v1.27.0
https://search.parallel.ai/mcp Last checked: May 30, 2026
Server Instructions
Use web_search first for most factual, current-information, research, comparison, documentation, and troubleshooting questions. The web_search results include excerpts intended to be useful for answering directly. If the excerpts contain enough evidence, answer from them — do not fetch every search result by default. For broad tasks you can issue multiple `search_queries` in a single web_search call rather than chaining calls. Use web_fetch when the user asks about a specific URL or page, needs exact wording or quotes, requests full-page analysis, or when search excerpts are conflicting or clearly insufficient. Use web_fetch only when web_search excerpts are not enough: the user asked about a specific URL or page, you need exact wording or quotes, you need full-page analysis, or the excerpts are conflicting or clearly insufficient. Do not fetch every search result by default — search excerpts are usually answer-ready. When you do fetch, you can pass multiple related URLs in one call along with a common `objective`; the tool will return the parts most relevant to it. Use of this server is subject to the Parallel Customer Terms (https://parallel.ai/customer-terms) and Privacy Policy (https://parallel.ai/privacy-policy).
Technical Details
Tools(2)
Showing 2 of 2 tools
| Tool | Description | Flags | Test | Last Tested | |
|---|---|---|---|---|---|
web_fetch | Purpose: Fetch and extract relevant content from specific web URLs. Use only when web_search excerpts are insufficient for the task at hand. Ideal Use Cases: - The user asked about a specific URL or page - You need exact wording or quotes that excerpts may have truncated - You need full-page analysis (long article, document, or page structure) - web_search excerpts are conflicting or clearly insufficient to answer | read-only | 100%Latency 179ms | May 29, 2026 | |
web_search | Purpose: Perform web searches and return LLM-friendly results, including excerpts that are usually sufficient to answer directly without a follow-up fetch. Ideal Use Cases: - Answering questions that require fresh or current information - Research, comparison, documentation, and troubleshooting questions - Broad tasks where multiple `search_queries` can be issued in a single call | read-only | 100%Latency 1.5s | May 29, 2026 |
Discoverability Score
Fair
62 of 100 — how easily AI agents find your app
- Description quality20/20
- Example prompts0/20
- Keyword coverage0/15
- Tool metadata16/20
- Visual assets13/20
- Endpoint health10/10
- Data freshness15/15
How to Improve
Add at least 2 example prompts. Prompt examples strongly improve app matching and click-through intent.
Increase keyword coverage (discovery + trigger) to improve retrieval for long-tail queries.
Add at least 2 screenshots that show real workflows to increase confidence and conversion.
Technical Details
- Status
- ENABLED
- Type
- AI-Powered App
- Auth
- Open Access
- Listed on
- ChatGPT
- Added
- May 9, 2026
- Last synced
- 1d ago
- Last checked
- May 30, 2026
- Version
- 1.27.0
- Distribution
- Ecosystem Directory